ANT Evaluation of Internet Outages
What are Internet Outages?
Network outages vary in scope and cause, from the 5-day shutdown of Bangaldesh in July 2024 to Hurricane Beryl’s landfall in Texas in July 2024, fortunately much milder than Hurricane Harvey in 2017, to hundreds of small outages and sometimes not-so-small outages that occur every day.
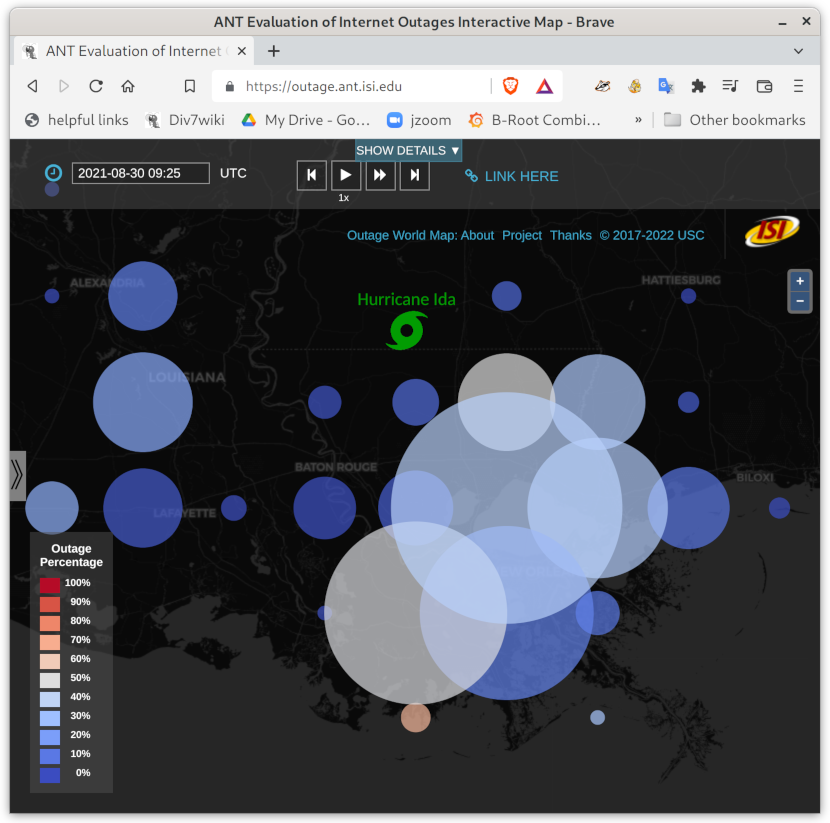
Outages matter because they allow us to judge the reliability of the Internet directly, and they sometimes allow us to infer things about the real world (like how widespread was a natural disaster).
How do we find outages?
We use Trinocular, our active probing system to track outages across the Internet, adaptively probing all /24 address blocks where enough address reply to pings (as of 2020: that’s about 5.3M blocks!). We develop new algorithms to identify outages and cluster them to events, providing the first visualization of outages. Finally, we report on Internet stability as a whole, and the size and duration of typical outages, using core-to-edge observations. We find that about 0.3% of the Internet is likely to be unreachable at any time, suggesting the Internet provides only 2.5 ``nines’’ of availability.
What Makes Trinocular Unique?
Trinocular is unique for several reasons:
-
It was the first system to track global IPv4 outages, with data 24x7 from Oct. 2013 (see the internet_outage_adaptive datasets) that is available to researchers at no cost.
-
Our outage website provides interactive access to our data since 2017, with continuous, near-real-time updates.
-
Our freely-available datasets have served as a benchmark against which to test alternative systems (such as Disco and CDN-based detection). We have incorporated feedback from what others learned to improve coverage in Trinocular, making it more sensitive and allowing us to grow coverage from 3M to more than 5M IPv4 /24 blocks.
Specific Outages
We have studied outages in the January/February Internet outage in Egypt corresponding to the Egyptian revolution, the March 2011 Tohoku earthquake off the coast of Japan, and the October 2012 Hurricane Sandy on the east coast of the U.S. We have a technical report describing our analysis of Hurricane Sandy. We studied the 2017 Hurricane Harvey, and recently 2018 Hurricane Florence.
An Outage Detection Algorithm
Our approach is described in the peer-reviewed paper: [1] and has been refined several times: [2] [3] [4]
- Guillermo Baltra and John Heidemann 2020. Improving Coverage of Internet Outage Detection in Sparse Blocks. Proceedings of the Passive and Active Measurement Workshop (Eugene, Oregon, USA, Mar. 2020). [PDF] Details
- Abdulla Alwabel, John Healy, John Heidemann, Brian Luu, Yuri Pradkin and Rasoul Safavian. 2015. Evaluating Externally Visible Outages. Technical Report ISI-TR-701. USC/Information Sciences Institute. [PDF] Details
- Lin Quan, John Heidemann and Yuri Pradkin 2014. When the Internet Sleeps: Correlating Diurnal Networks With External Factors. Proceedings of the ACM Internet Measurement Conference (Vancouver, BC, Canada, Nov. 2014), 87–100. [DOI] [PDF] Details
- Lin Quan, John Heidemann and Yuri Pradkin 2013. Trinocular: Understanding Internet Reliability Through Adaptive Probing. Proceedings of the ACM SIGCOMM Conference (Hong Kong, China, Aug. 2013), 255–266. [DOI] [PDF] Details
The full technical details are in the above papers.
A short, informal description: A Trinocular probers sends to each block (a /24 IPv4 prefix, that is, addresses in 1.2.3.*, where the first three parts are fixed), every 11 minutes (a “Trinocular round”) We probe multiple times, stopping when we get a positive reply, since that indicates the block is reachable and therefore up. We limit probing to 15 times per round, a traffic rate so low it does not have a noticeable effect on the target network.
We determine an outage has occurred after voting by 6 Trinocular probers running from different locations around the world. We use multiple locations to avoid interpreting a regional or local problem as an outage.
We add a number of other algorithms to the above basics: hole filling (to handle lost messages), precision improvement (to improve the timing of event start), gone-dark handling (to remove blocks that stop responding), full-block scanning (to avoid false outages in very sparse blocks), lone-address block recovery (to handle blocks with 2 or fewer addresses). These algorithms cover different conditions that might otherwise result in false outages.
We run two versions of our processing: batch processing includes all of our algorithms and happens every quarter. Near-real-time (NRT) processing happens continuously and includes only the basic algorithms. We report results in our outage website, with NRT data for recent results, and batch data for older results.
Where Next
- Browse near-real-time outages on a world map
- View animations of outages: Hurricane Sandy in 2012 in it50j, the Aug. 2014 Time Warner outage in a17all, and Hurricane Harvey in a29
- Browse a network-centric view of outages here
- Our outage datasets
- For more technical description, please refer to our peer-reviewed paper [1] or earlier technical reports on outage detection [2] and Hurricane Sandy [3]
- John Heidemann gave talks about our analysis of Hurricane Sandy at NANOG57, FCC Workshop on Network Resiliency (with video), and the CAIDA AIMS 2013 workshop.
- John Heidemann reported about long-term challenges in collected outage data at the CAIDA AIMS 2017 workshop.
- Lin Quan, John Heidemann and Yuri Pradkin 2013. Trinocular: Understanding Internet Reliability Through Adaptive Probing. Proceedings of the ACM SIGCOMM Conference (Hong Kong, China, Aug. 2013), 255–266. [DOI] [PDF] Details
- John Heidemann, Lin Quan and Yuri Pradkin 2012. A Preliminary Analysis of Network Outages During Hurricane Sandy. Technical Report ISI-TR-2008-685b. USC/Information Sciences Institute. [PDF] Details
- Lin Quan, John Heidemann and Yuri Pradkin 2012. Detecting Internet Outages with Precise Active Probing (extended). Technical Report ISI-TR-2012-678b. USC/Information Sciences Institute. [PDF] Details